Por que os LLMs enfrentam dificuldades: limites de matemática, dados estruturados e raciocínio da IA

Equipe Moveo AI
in
✨ Mergulhos Profundos em IA

Modelos de Linguagem Grandes são extraordinários com linguagem, mas não são calculadoras. A força central deles é modelar distribuições de probabilidade sobre texto, não executar lógica formal ou aritmética com garantia de precisão. Para empresas que requerem confiabilidade, auditabilidade e conformidade, essa diferença é decisiva.
Este artigo explica por que modelos que parecem brilhantes na prosa muitas vezes falham com números, o que está acontecendo por trás das cenas e como projetar sistemas que produzem resultados exatos e auditáveis em fluxos de trabalho empresariais reais.
LLMs são preditores de palavras, não calculadoras
Modelos de LLM baseados em transformadores otimizam para o próximo token que é mais provável de aparecer, dado o contexto. Esse objetivo é perfeito para redação fluente, sumarização, tradução e sugestões de código. Isso não garante que fórmulas de interesse, risco, imposto ou desconto sejam calculadas exatamente.
Pense sobre isso desta forma. A linguagem é estatística. A aritmética é baseada em regras. Um modelo pode aprender que “meu nome é” muitas vezes precede um primeiro nome. Não há margem em “62,62.3 × 73.98” ou em “composto de 2,75 por cento por 13 meses usando arredondamento bancário”. A aritmética requer procedimentos determinísticos passo a passo. Perto o suficiente está errado.
Mesmo fatos simples como 1 + 1 = 2 são frequentemente recuperados como padrões memorizados em vez de serem executados como algoritmos gerais. Assim que você passa para números maiores, formatos desconhecidos ou políticas de arredondamento intrincadas, a aparente certeza evapora.
Probabilidade vs. Lógica Baseada em Regras
Quando um LLM responde com um número, ele está produzindo uma sequência de tokens que parece plausível. A Matemática não recompensa plausibilidade. Ela recompensa exatidão. A sequência única e correta de dígitos para uma multiplicação de cinco dígitos é um padrão muito raro em texto comum. O modelo muitas vezes escolherá um padrão mais comum que parece certo para o leitor em vez do único correto exigido por um livro de contabilidade.
É por isso que parágrafos confiantes de um modelo de linguagem ainda podem esconder um único dígito errado que falha na reconciliação, dispara uma exceção de conformidade ou leva a um resultado injusto para o cliente.
O problema do "Papagaio Estocástico" aplicado a números
Essa limitação está enraizada no "Dilema do Papagaio Estocástico", um termo usado para descrever LLMs que geram linguagem convincente sem uma verdadeira compreensão do significado subjacente.
Os LLMs são treinados para continuar o texto de uma maneira que corresponda a padrões de distribuição. Eles não possuem uma noção interna de variáveis, axiomas ou operadores com semântica garantida. Quando tarefas dependem de semântica estrita, como o cálculo de juros sobre um saldo rotativo ou a conversão de pontos base em alterações percentuais ao longo de períodos, um gerador de texto plausível produzirá rotineiramente respostas que leem bem e calculam mal.
Em ambientes regulados, isso é inaceitável. Você precisa de sistemas que computem exatamente e expliquem como o fizeram.
→ Saiba mais: LLM Wrappers vs. Multi-Agent AI da Moveo: Por que Resultados Reais Precisam de Arquitetura Real
A tokenização é a barreira invisível para a razão numérica
A raiz mais técnica do problema da matemática LLM está em como o modelo tokeniza números.
Na maioria dos LLMs, o texto é dividido em tokens de subpalavras otimizados para a frequência da linguagem, não para a estrutura dos dígitos. Essa escolha de design sabotou silenciosamente a aritmética.
Como a tokenização prejudica os números
A mesma quantidade pode ser dividida de maneira diferente. O número “87439” pode se tornar tokens como “874” e “39” em um contexto, “87” e “439” em outro, ou um único token em outro lugar. O modelo não percebe consistentemente o valor posicional. Ele vê pedaços arbitrários de texto.
A formatação altera o padrão estatístico. Os valores 12.345 e 12345 e 12 345 e 12.345 são iguais sob diferentes convenções de localidade, mas cada forma produz uma sequência de tokens diferente com diferentes priors de próximo token.
Decimais e notação científica se fragmentam. A igualdade entre 0.007, 7.0e-3 e 7×10^-3 não é codificada. Cada representação tokeniza e se comporta de forma diferente.
Zeros à frente e identificadores distorcem expectativas. Uma quantidade como 000123 pode ser um código, um SKU ou um número inteiro com preenchimento. Os tokens ao seu redor encorajam o modelo a continuar com tipos de texto muito diferentes.
Cadeias de transporte mais longas são raras em textos de treinamento. Os modelos podem imitar aritmética curta vista com frequência, e então tropeçar em operações de sete a dez dígitos onde a propagação do transporte deve ser precisa em várias posições.
Esse mesmo mecanismo explica por que os modelos muitas vezes falham em contar caracteres em uma palavra. Por exemplo, “morango” pode ser dividido em pedaços de subpalavras em vez de letras individuais, de modo que o modelo não rastreia de forma confiável quantos r's estão presentes.
O resultado é previsível. Sem uma representação consciente de números ou uma calculadora externa, o modelo não pode executar aritmética de maneira confiável em diferentes formatos, tamanhos e políticas.
Por que o contexto ainda importa
O contexto não é uma panaceia para a aritmética, mas é essencial para a correção em fluxos de trabalho de ponta a ponta. O modelo não pode calcular exatamente, mas pode selecionar os dados corretos, a política correta e as instruções corretas para um motor determinístico se você fornecer o contexto apropriado.
Forneça fontes de dados autorizadas. Identifique a fonte de verdade para saldos, a tabela correta de taxas de câmbio e as datas efetivas que se aplicam.
Defina política e semântica. Especifique regras de arredondamento, convenções de contagem de dias, limites de taxas, manuseio de moeda e formatação de localidade como restrições verificáveis por máquina.
Descreva esquemas e campos. Anote qual coluna representa capital versus juros, qual sinal indica programas de dificuldade e qual métrica é uma divulgação regulatória.
Com o contexto certo, o modelo pode orquestrar o cálculo correto, embora nunca deva tentar a aritmética dentro da camada do modelo.
Modos típicos de falha que você verá
Abaixo estão falhas concretas que aparecem em sistemas reais.
Desvio na multiplicação longa. Peça 48.793 × 7.604. Um LLM simples muitas vezes produz um resultado que está incorreto por centenas ou milhares, porque a propagação de transporte entre múltiplos dígitos não é aprendida de forma consistente. O número pode até ter o comprimento certo e parecer plausível à primeira vista.
Desajuste na política de arredondamento. Um reembolso de cliente requer arredondamento bancário para duas casas decimais. O modelo, em vez disso, aplica arredondamento para cima e retorna 31,76 onde a política requer 31,75. A diferença é pequena isoladamente, mas quebra regras de reconciliação e auditoria em grande escala.
Confusão de localidade. A entrada “12.345” é um decimal no formato dos EUA e um marcador de milhares em muitos contextos da UE. Um LLM que o trata como 12,345 em um passo e 12.345 em outro passo irá silenciosamente envenenar um pipeline.
Erros de unidade. Uma tarefa de precificação pede uma mudança de 25 pontos-base, que é 0,25 por cento. O modelo aplica erroneamente 25 por cento. A narrativa parece correta. O número é catastrófico.
Interpretação incorreta do período. Uma taxa anual de 7,5 por cento é acidentalmente tratada como uma taxa mensal em uma fórmula de amortização. O pagamento se inflaciona para um valor absurdo, mas a explicação soa convincente.
Estes não são casos exóticos. Eles aparecem sempre que as entradas ficam maiores, os formatos variam ou a política é sutil.
→ Saiba mais: Aperfeiçoamento, RAG ou Engenharia de Prompt? Guia de Decisão do LLM
Sistemas Híbridos e Raciocínio Programático
A solução para falhas no processamento de dados de LLM e raciocínio numérico é simples. Não peça a um LLM para ser uma calculadora, peça para planejar, explicar e chamar um.
Um padrão híbrido robusto se parece com isso.
Descarregar matemática para ferramentas. Direcione toda a lógica aritmética e de políticas para calculadoras e serviços determinísticos.
Padronizar entradas. Normalize locais, moedas, separadores, sinais e unidades antes de planejar.
Fixar as regras uma vez. Centralize arredondamentos, políticas de juros e taxas em uma única fonte de verdade.
Verificar cada resultado. Adicione verificações de intervalo, testes de reconciliação e computação dual em montantes críticos.
Usar o LLM para orquestração. Deixe que ele gerencie intenção, planejamento, contexto e explicações, nunca números finais.
Esta é a arquitetura que as equipes líderes implementam em produção. Ela mantém a linguagem onde a linguagem brilha e move a aritmética e a política onde a certeza reside. Se você já viu plataformas de IA maduras no campo, provavelmente viu esse padrão. É também o padrão que usamos quando construímos agentes de nível empresarial.
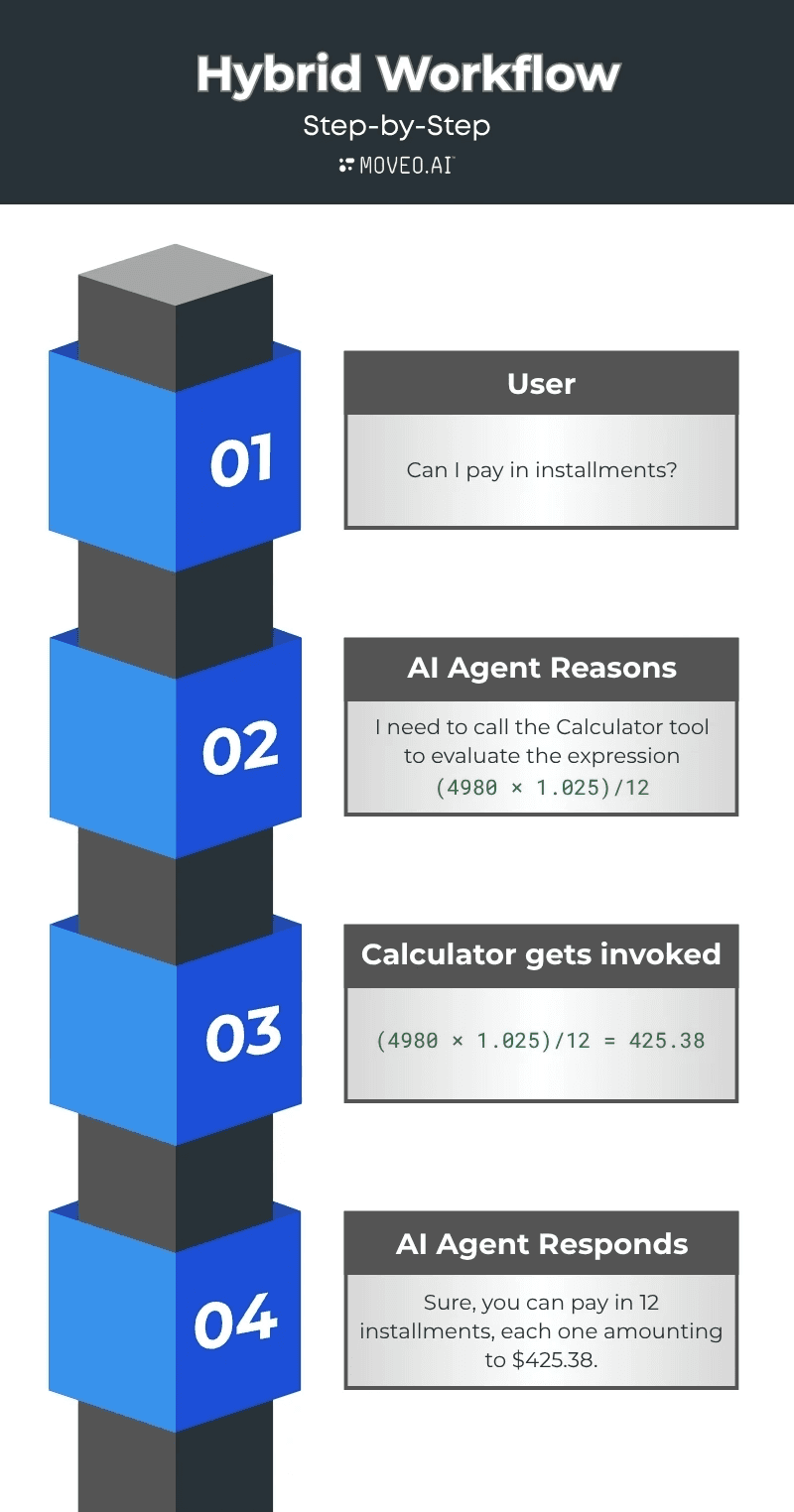
Exemplo: Negociação de pagamento com planos de parcelamento conformes
Cenário
Um agente de IA negocia um plano de pagamento para um saldo devedor de $4.980. A política permite um plano de parcelamento de 12 meses com 2,5% de juros e arredondamento padrão de duas casas decimais.
O que um LLM simples tende a fazer
Um LLM simples frequentemente tentará “resolver” a matemática dentro do modelo ao recordar um padrão familiar. Ele pode multiplicar o saldo por um único fator e dizer que o total é 4980 × 1,025, depois dividir por 12.
Isso é tanto uma simplificação exagerada quanto muito provavelmente numericamente incorreto na prática, uma vez que ignora periodização, manuseio de taxas e política de arredondamento. O modelo está prevendo tokens que parecem uma fórmula em vez de executar o cálculo correto.
O que uma arquitetura híbrida faz em vez disso
O modelo planeja os passos e escreve a fórmula exata e as regras da política, mas não calcula os números. Ele seleciona o tratamento adequado da taxa de 2,5%, decide se é aplicada como juros simples anuais ou como uma taxa periódica mensal para amortização, e especifica a política de arredondamento.
Então, ele chama uma ferramenta de calculadora para executar a matemática. A calculadora retorna o pagamento mensal preciso e o cronograma completo até o centavo. O modelo explica o resultado em linguagem simples e registra as entradas, versão da política e saídas para auditoria. Isso mantém a interpretação da linguagem e da política no modelo, e mantém a aritmética em um componente determinístico onde é garantido que esteja correta.
O que não exagerar
Mais chamadas para o LLM em estilo de corrente de pensamento, um modelo maior ou mesmo um modelo “mais inteligente” não fará os números ficarem corretos de forma confiável. A limitação é arquitetônica. LLMs baseados em transformador são geradores de texto probabilísticos, não calculadoras exatas de regras. Um prompting maior ou mais elaborado pode ajudar o modelo a ler e raciocinar sobre o contexto, mas a aritmética pertence a ferramentas determinísticas que implementam regras, tipos e testes.
Uma lista de verificação prática para líderes
Os LLMs falham na análise de dados e matemática devido à sua natureza: eles são modelos de linguagem otimizados probabilisticamente para fluência, não para precisão baseada em regras.
A tokenização elimina a estrutura posicional necessária para a aritmética. Os dados de treinamento raramente cobrem a cauda longa de cálculos financeiros e operacionais reais.
A solução é um sistema híbrido no qual o modelo orquestra e ferramentas determinísticas realizam o cálculo. Com o contexto, a política e o registro de auditoria corretos, você obtém correção, explicabilidade e conformidade sem sacrificar a inteligência conversacional que os usuários valorizam.
É assim que equipes modernas entregam IA em que você pode confiar.
Para implantar com sucesso os LLMs em ambientes que exigem alta precisão numérica e conformidade, siga esta lista de verificação:
Roteie toda a lógica aritmética e vinculada à política para ferramentas determinísticas. Trate isso como um requisito obrigatório.
Normalize os formatos numéricos na entrada. Resolva localidade, moeda, separadores, sinais e unidades antes de planejar.
Codifique políticas de arredondamento, juros e taxas em uma única fonte de verdade. Reutilize essas regras em todos os lugares.
Adicione camadas de verificação. Use verificações de intervalo, testes de reconciliação e computação dual em valores críticos.
Faça o modelo responsável pela compreensão da intenção, geração de planos, recuperação de erros, coleta de contexto e explicações claras. Não o deixe gerar números finais.
Esteja à frente da estratégia de IA. Siga a Moveo.AI no LinkedIn para mais insights de especialistas sobre como construir agentes LLM prontos para produção e sistemas híbridos.
Pronto para construir uma IA em que você pode confiar? Fale com nossos especialistas em IA hoje para projetar sua solução LLM robusta e pronta para conformidade.