Por que o GPT-5 não será suficiente para implantar Agentes de IA?

Panos
Co-fundador & CEO
in
🏆 Insights de Liderança

Uma pergunta comum e razoável é: Por que investir na construção de arquiteturas complexas de Agentes de IA se versões futuras do GPT podem eventualmente incluir toda a funcionalidade necessária prontamente?
Por que não esperar pelo GPT-5 para lidar com tudo?
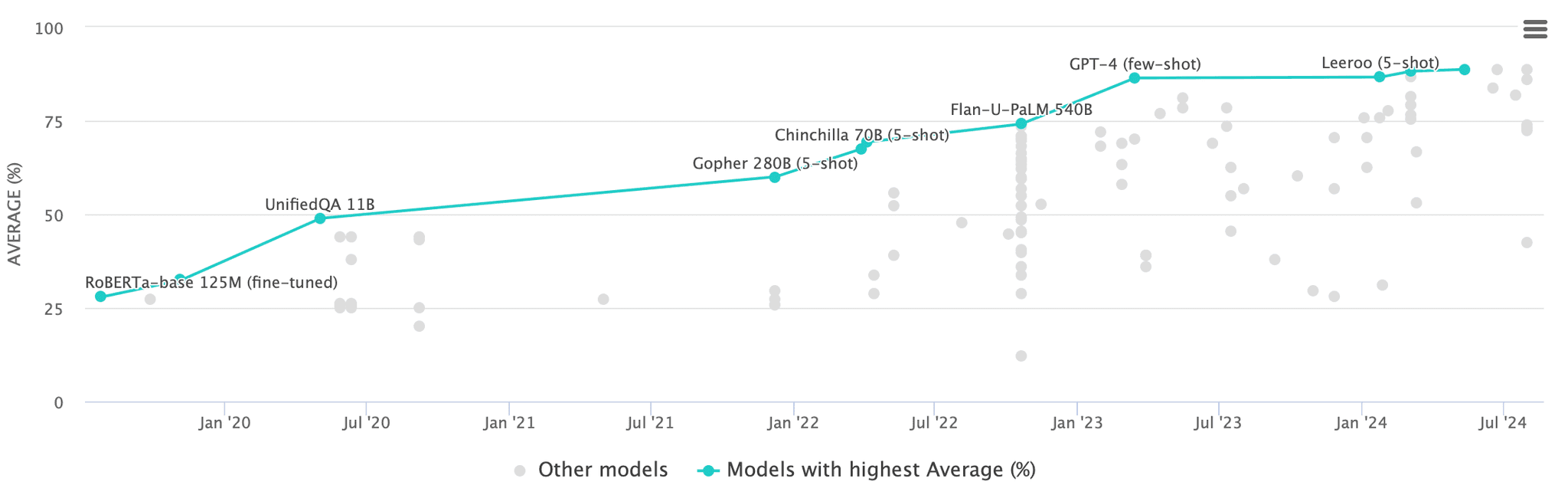
A resposta está na observação de que o progresso nas arquiteturas de transformadores—o tipo de rede neural por trás dos grandes modelos de linguagem—parece estar desacelerando. Ao olhar para benchmarks projetados para avaliar o desempenho dos LLMs, como o Massive Multitask Language Understanding (MMLU), observamos um platô notável nos avanços recentes. O GPT-4 estabeleceu um recorde em 2023 com uma impressionante pontuação de 86,4%, quase dobrando o desempenho do GPT-3 desde sua estreia em 2020. No entanto, desde o lançamento do GPT-4, modelos mais novos mostraram apenas melhorias marginais em comparação ao salto significativo do GPT-3 para o GPT-4. Por exemplo, o GPT-o1, o mais recente modelo de raciocínio da OpenAI, pontua cerca de 92,3% no MMLU, apenas um aumento de 6% em relação aos 86,4% do GPT-4. Isso sugere que, embora os avanços continuem, as descobertas transformadoras que definiram as iterações anteriores estão se tornando mais difíceis de alcançar.
Uma das principais razões pelas quais os modelos mais novos apresentam apenas melhorias marginais pode ser encontrada em uma publicação recente, intitulada No “Zero-Shot” Without Exponential Data. O artigo apresenta evidências de que dados adicionais de treinamento proporcionam retornos decrescentes nas melhorias de desempenho dos LLMs, exibindo uma tendência logarítmica à medida que os dados aumentam.
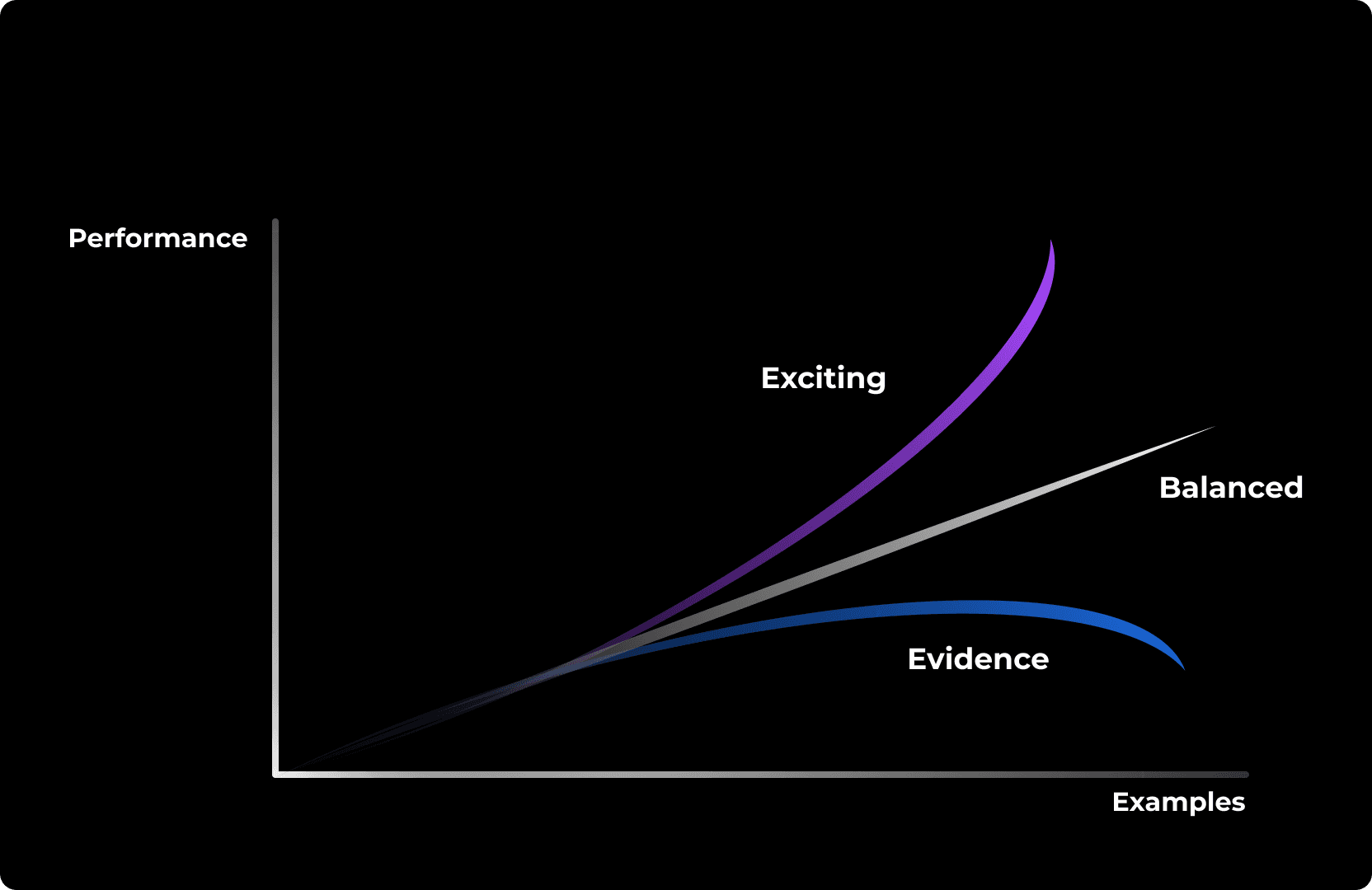
Se essa tendência se mantiver verdadeira, conforme sugerido pelas evidências no artigo, então nos deparamos com uma situação em que os LLMs precisarão de dados exponenciais a mais para melhorar rumo ao AGI (Inteligência Geral Artificial). O problema é agravado pelo fato de que, com aproximadamente 15 trilhões de tokens, os conjuntos de treinamento atuais de LLM já estão se aproximando do limite superior de texto público de alta qualidade disponível. Para o inglês sozinho, as estimativas sugerem um máximo de 40 a 90 trilhões de tokens, significando que estamos nos aproximando do ponto de saturação de dados utilizáveis e disponíveis.
Além disso, as tendências históricas indicam que os requisitos de dados do modelo aumentaram dez vezes a cada nova geração (GPT-2 para GPT-3 para GPT-4 exigiram todos 10x ou mais dados). Embora o GPT-5 ainda possa alcançar melhorias incrementais por meio de uma coleta de dados expandida e otimizações menores, a escalabilidade sozinha é improvável que sustente a mesma trajetória para as gerações futuras. Para modelos no nível do GPT-6 e além, alcançar um progresso significativo provavelmente exigirá descobertas em novas arquiteturas ou paradigmas inteiramente novos que ainda não foram descobertos.
Dada a atual situação da pesquisa e das evidências disponíveis, está longe de ser certo que modelos futuros como o GPT-5 ou GPT-6 proporcionarão melhorias na mesma ordem de magnitude que seus predecessores. O argumento de que "levou três anos para o GPT-4 superar o GPT-3" é fraco quando analisado: o salto de desempenho do GPT-4 foi principalmente impulsionado por escalabilidade—arquiteturas maiores e 10x mais dados de treinamento.
Essa abordagem, no entanto, enfrenta não apenas retornos decrescentes—como sugerem as evidências—mas também estamos nos aproximando dos limites práticos dos dados de texto de alta qualidade disponíveis. O progresso adicional dependerá menos de simplesmente escalar e mais de inovação em novas arquiteturas ou paradigmas de treinamento inteiramente diferentes; sem tais descobertas, os avanços rápidos que testemunhamos nos últimos anos podem inevitavelmente desacelerar. Um contra-argumento é que ainda existe abundância de dados não textuais, como imagens e vídeos, que são fontes ricas de informação. De fato, uma parte significativa da cognição humana vem da observação de situações visualmente, em vez de por meio de texto. Embora modelos que processam imagens e vídeos já estejam sendo desenvolvidos e modelos multimodais estejam surgindo, essas tecnologias ainda estão em seus estágios iniciais—especialmente no campo da geração de vídeo. Pesquisadores em grandes departamentos de P&D estão tentando aproveitar esses dados não explorados criando modelos capazes de reconhecer situações em vídeos e imagens, convertendo-os em texto e, assim, enriquecendo os LLMs. Embora isso traga promessas, destaca a necessidade de abordagens inovadoras em vez de confiar apenas na escalabilidade dos modelos existentes.