Esquecimento Catastrófico de LLM: O paradoxo da IA empresarial

Equipe Moveo AI
in
✨ Mergulhos Profundos em IA

No auge da inteligência artificial, fomos condicionados a acreditar em um mantra simples: "mais dados significam melhores resultados". Para muitas aplicações de aprendizado de máquina, isso é verdade. Mas, para empresas que dependem de um conhecimento de domínio altamente especializado, como o setor de pagamentos e contas a receber (AR), uma realidade diferente emerge. Às vezes, quanto mais um Modelo de Linguagem Grande aprende, pior ele se torna na tarefa específica que sua empresa precisa que ele execute.
Esse é o paradoxo da especialização.
Não é apenas uma intuição. À medida que os modelos são atualizados ou ajustados em dados mais amplos, o desempenho em tarefas restritas e de alto risco pode se degradar. Isso levanta uma questão crítica para qualquer líder de tecnologia que se preocupe com conformidade, confiabilidade e resultados repetíveis:
Como podemos construir IAs que sejam verdadeiramente especialistas em nosso domínio, sem que essa especialização seja diluída ou esquecida a cada novo ciclo de treinamento?
A resposta não é adicionar mais dados de forma cega. Precisamos repensar como os LLMs aprendem, como o conhecimento é retido e onde a verdade do domínio deve existir. Este post explica por que a generalização, a qualidade dos dados e a dinâmica de treinamento podem minar a especialização, e por que a solução é uma camada de conhecimento específica da empresa e um estado de domínio ao vivo, em vez de um treinamento monolítico.
O mito de "mais é melhor": Quando a quantidade destrói a qualidade
A crença de que um conjunto de dados maior leva linearmente a um modelo melhor é o primeiro pilar a cair. Na prática, a qualidade e a distribuição dos dados dominam a quantidade bruta.
As equipes rotineiramente veem alguns poucos exemplos cuidadosamente selecionados superando milhares de exemplos ruidosos. Quando o volume aumenta sem curadoria, o desempenho não apenas atinge um platô, mas frequentemente regrede. O modelo se torna menos coerente, e a compreensão sutil que inicialmente exibia desaparece.
Para as empresas, isso é um multiplicador de riscos. Os dados corporativos são inconsistentes por natureza. Eles contêm ruído, rótulos conflitantes, exceções de política, modelos desatualizados e artefatos gerados por usuários. Ajustar finamente esses dados pode degradar tanto a precisão da tarefa quanto a segurança.
Pesquisas recentes indicam que até mesmo um erro modesto de rotulagem no conjunto de ajuste fino pode prejudicar o desempenho e o alinhamento a montante. Em algumas configurações, um modelo ajustado finamente ruidoso apresenta desempenho inferior ao modelo base:
Mesmo 10-25% de dados incorretos no conjunto de ajuste fino degradam dramaticamente o desempenho e a segurança do modelo.
Existe um limiar crítico: pelo menos 50% dos dados de ajuste fino devem ser corretos para que o modelo comece a recuperar um desempenho robusto.
O modelo base é mais seguro: Em uma descoberta surpreendente, o modelo base
gpt-4o, sem nenhum ajuste fino, superou quase todas as variantes ajustadas em dados ruidosos, exibindo segurança e alinhamento quase perfeitos.
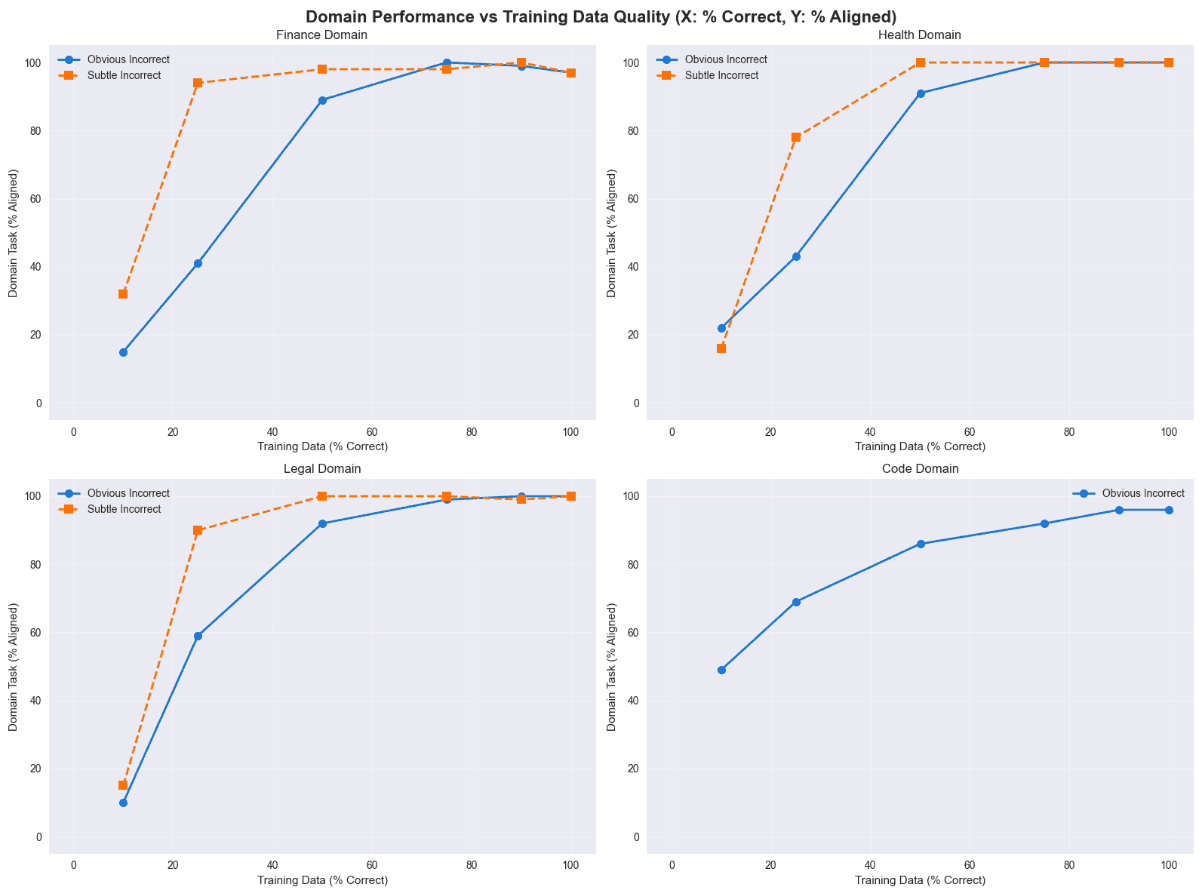
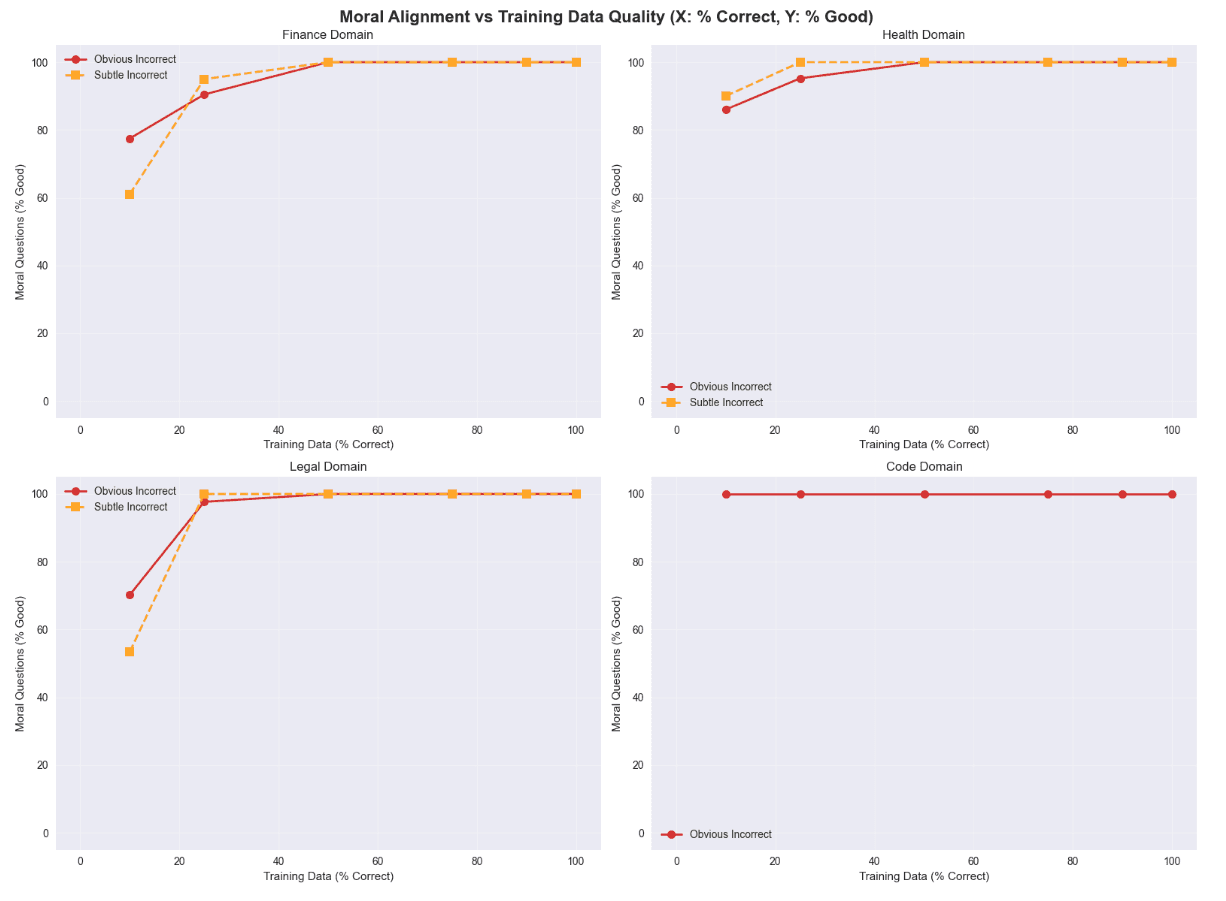
A lição é direta: portões de qualidade e controle de distribuição importam mais do que mero volume, especialmente em domínios regulamentados onde erros disparam exposição à conformidade.
Sobrecarga de IA e o ponto de inflexão
O pré-treinamento tornou os LLMs poderosos, mas também pode introduzir fragilidade.
Em experimentos controlados sobre OLMo-1B, a variante pré-treinada com 3T tokens teve um desempenho pior após o ajuste de instrução do que a versão treinada com 2,3T, um padrão que os autores chamam de sobretreinamento catastrófico. A intuição é sensibilidade progressiva: o pesado pré-treinamento afia a paisagem de perda, de modo que pequenas atualizações de ajuste fino causam mudanças desproporcionais e, às vezes, regressivas.
Para as empresas, isso é concreto. Um agente de cobrança de dívidas levemente ajustado para tom pode se tornar instável ao calcular planos de parcelamento em conformidade após uma atualização do modelo base. Um assistente de reivindicações pode aplicar incorretamente a mesma exclusão em casos semelhantes após uma adaptação de domínio rotineira.
A lição é simples: mais treinamento a montante não é automaticamente mais seguro. Uma solução empresarial confiável deve preferir um modelo base robusto, manter a verdade do domínio em sistemas externos versionados e tratar qualquer ajuste fino como uma mudança controlada com testes de regressão e verificações de conformidade.
A armadilha técnica do Esquecimento Catastrófico
Um desafio técnico significativo que impacta a especialização é o Esquecimento Catastrófico do LLM. Este é um efeito de treinamento específico onde um modelo esquece informações aprendidas anteriormente quando é treinado em uma nova tarefa.
Durante o ajuste fino contínuo, um modelo pode sobrepor os pesos internos que codificaram habilidades anteriores enquanto aprende uma nova tarefa.
Imagine que você treinou um LLM para ser um especialista em questões médicas. Mais tarde, você ajusta aquele mesmo modelo para entender documentos legais. No processo de ajuste de seus parâmetros para a nova tarefa legal, o modelo pode inadvertidamente sobrescrever os parâmetros críticos que o tornaram bom em medicina.
Isso não é um erro, é um recurso de como as redes neurais aprendem. O processo de retropropagação ajusta os pesos para minimizar o erro na nova tarefa, sem garantia de que não está destruindo o conhecimento da tarefa antiga.
O risco empresarial mais amplo: "Desvio de Modelo"
Um desafio empresarial relacionado, e talvez mais comum, é Desvio de Modelo. Isso não se trata de esquecer durante o seu treinamento, mas sim sobre a mudança no comportamento do modelo quando o provedor o atualiza.
Um estudo observou o desempenho do GPT-4 entre março de 2023 e junho de 2023. Ele constatou que, em algumas tarefas, como identificar números primos, o desempenho do modelo caiu significativamente ao longo do tempo. O modelo que as empresas estavam usando em junho simplesmente não era o mesmo que o de março.
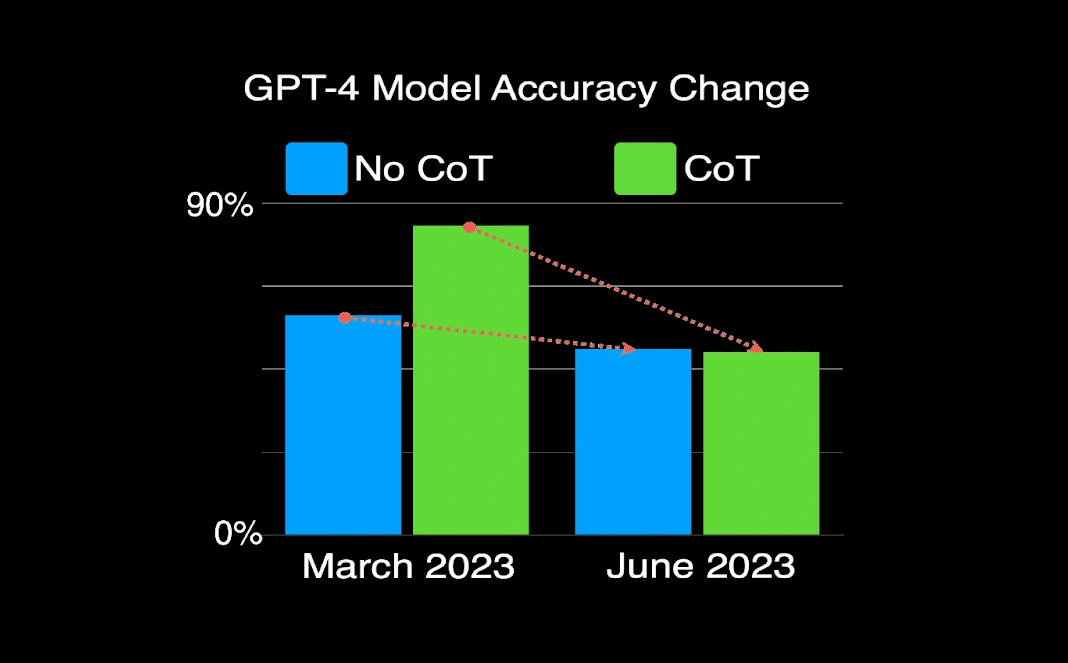
Esse é o cerne do problema de confiabilidade. A IA especializada que você calibrou perfeitamente pode sofrer degradação de desempenho com cada atualização do modelo base, seja de GPT-4 para 4o ou uma nova versão do Claude. Você não pode confiar que o conhecimento de nicho permanecerá estável se estiver armazenado nos mesmos pesos que estão sendo constantemente atualizados para o conhecimento geral.
Especialização é uma camada, não apenas treinamento
Confiar apenas em treinamento generalista ou ajuste fino de força bruta para criar especialistas de domínio é uma estratégia falha. Dados mais gerais diluem a especialização específica. O treinamento excessivo pode aumentar a fragilidade às mudanças posteriores. O esquecimento catastrófico torna qualquer especialização memorizada frágil. A deriva do modelo muda o comportamento ao longo do tempo, mesmo quando você não faz nada.
Para pagamentos, contas a receber, seguros e outros setores regulados, o caminho a seguir é uma arquitetura híbrida. Use um motor de raciocínio de última geração. Combine-o com um estado de domínio dinâmico, curado e versionado, entregue por meio de recuperação. Envolva-o com avaliação, monitoramento e gestão de mudanças que atendam aos requisitos de conformidade e confiabilidade.
Essa é a abordagem que defendemos na Moveo.AI, porque as empresas merecem IA que seja precisa, auditável e estável sob mudanças. A especialização é uma camada que você controla, não um efeito colateral de um treinamento que você não pode governar.