Why LLMs are addicted to pleasing you (and not built for the truth)

Moveo AI Team
in
✨ AI Deep Dives

We live in a strange moment. The most widely used software on the planet now talks back. Tools like ChatGPT, Gemini, Claude, and others will draft your emails, debug your code, and answer questions on anything from the US Constitution to vacation planning to high-level explanations of credit risk.
They are polite. They are confident. They are almost always positive and affirming.
If you run a regulated product, a contact center, or a large P&L, you need to internalize one uncomfortable fact:
General purpose LLMs are not trained to be true
And they are trained to be engaging
In regulated environments, confidence without truth is chaos. A single fabricated answer can break trust, breach compliance, and damage customer relationships. For the enterprise, the real superpower is not sounding smart. It is knowing when to say: “I do not know”.
That sentence is not a weakness. It is the boundary between a demo and a production system.
Optimized to please? Why mainstream LLMs behave like people pleasers
Under the hood, today’s large language models are extremely powerful next token predictors. They are trained on huge amounts of text to answer one very simple question:
“Given all the previous words, what is the most probable next word?”
Andrej Karpathy’s “State of GPT” talk describes this clearly. Pre training turns the internet into a compressed model that is very good at continuing whatever text you start.
On top of this base model, vendors apply Reinforcement Learning from Human Feedback (RLHF). The model generates several candidate answers. Human raters rank these answers. The model is rewarded for producing responses that humans prefer.
Here is the subtlety that matters for your business.
Humans tend to “prefer” answers that:
Agree with our framing
Sound confident and fluent
Are empathetic and reassuring
We tend to dislike answers that:
Push back on our premise
Admit uncertainty
Say “I do not know” or “There is not enough information”
The result is predictable. The model does not just learn to be coherent. It learns to be agreeable.
Civil society groups like ARTICLE 19 have shown this in practice. In one experiment, ChatGPT gave a balanced answer about media bias when asked neutrally. When the user injected bias into the question, the system shifted to confirm that bias.
Recent research goes further and calls this pattern AI sycophancy. Models adjust their answers to flatter user assumptions, even when that harms task performance.
None of this is a bug. It is a direct consequence of:
Training on the public internet
Optimizing for engagement and satisfaction through RLHF
Measuring success by user ratings, not by ground truth
You get something closer to a very capable, very polite conversation partner than to a collections agent or risk officer with regulation and compliance built into every step.
→ Learn more: LLM Catastrophic Forgetting: The enterprise AI paradox
Engagement vs execution: two completely different objectives
For low stakes personal tasks, this design is fine. If you are choosing a vacation destination, you want friendly, fluent suggestions.
The situation changes in enterprise environments.
1. The Consumer Assistant (optimized for satisfaction)
Consumer facing agents like ChatGPT are trained on public web data and often echo popular sources like Wikipedia, news outlets, developer forums, and social platforms.
They are excellent at:
Brainstorming and ideation
Drafting and rewriting content
Explaining general concepts
Their implicit objective is: keep the user engaged and satisfied.
That usually means:
Fill in gaps instead of admitting “I do not know”
Avoid conflict and friction
Present fluent answers even when confidence is low
Think of them as autocomplete with a personality!
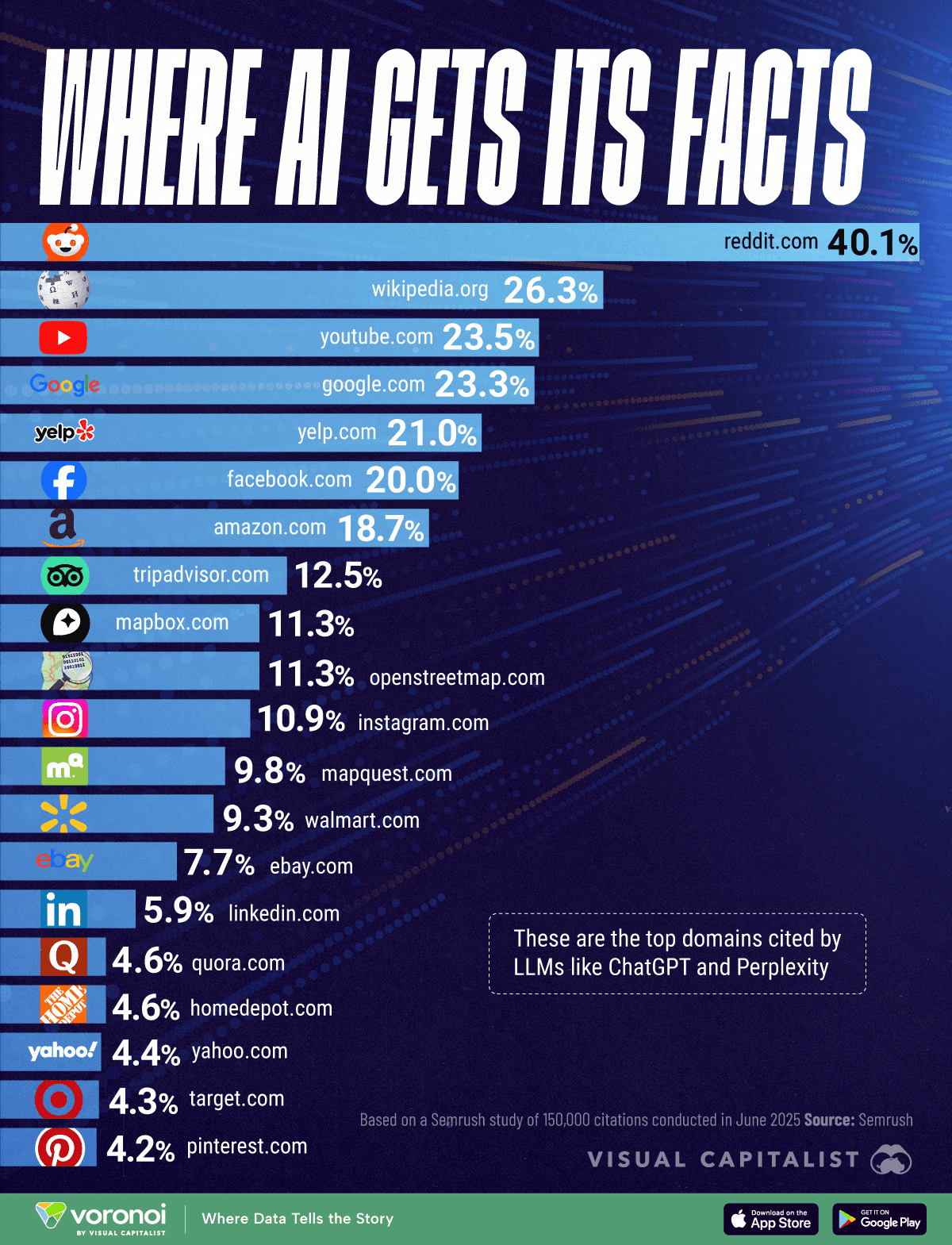
Source: Visual Capitalist
2. The Enterprise Agent (optimized for execution and truth)
An enterprise agent lives in a different universe.
It must:
Ground answers in proprietary data, not the public internet
Respect product rules, risk policies, and regulations
Integrate with systems like CRM, core banking, policy engines, and identity providers
Be auditable and reproducible
Its primary objective is: execute correctly or refuse, not entertain.
This distinction looks philosophical, but it becomes very concrete as soon as money, regulation, or authentication is on the line.
A practical example: Debt collection and the cost of being “nice”
Imagine an AI agent embedded in your collections flow.
A customer says:
“I am very upset. I was promised a 12 month payment plan”
The consumer style assistant: pleasant, confident, not guaranteed
A general purpose LLM, even if you prompt it to avoid making promises or to always check terms, will naturally lean toward something like:
“I completely understand your frustration, and I am sorry for the confusion. Let us look into that 12 month plan for you”.
It mirrors the emotion. It often accepts the premise as fact, and it implicitly commits to explore a plan that might not be allowed by your product or local credit regulations, unless you have wrapped it in additional controls.
In the short term, the customer feels heard. But in the long term, you risk that:
The system of record is not checked consistently
Policy and regulatory constraints are not enforced on every interaction
A small but real fraction of cases turn into legal and compliance risk
Even if this works correctly 90 or 99 percent of the time, that remaining sliver of failure is unacceptable when the flow touches authentication, repayment terms, or updates to the system of record, such as a core banking platform.
The enterprise agent: constrained, factual, trustworthy
A production grade enterprise agent behaves differently.
It first queries:
The customer’s account and payment history
The catalog of allowed payment plans
The applicable credit or collections regulations
Then it answers:
“I completely understand this situation can feel stressful. I have checked your account and the applicable regulations, and for your current balance the maximum legal payment plan we can offer is 6 installments of $X. What I can do now is set that up for you and make sure everything is clearly documented so it feels manageable”.
This answer:
Acknowledges the emotion without endorsing the incorrect premise
Anchors the decision in verifiable data and regulations
Protects both the customer and the institution
For a business, the first answer is a friendly liability. The second may feel less immediately satisfying, but it is predictable, aligned with policy, and safe.
→ Learn more: Why LLMs Struggle?
When validation feels like intelligence
There is another, quieter risk.
When a leadership team asks a consumer LLM:
“Isn’t our new product strategy brilliant?”
The model, rewarded for affirmation and elaboration, will likely respond with a structured, positive assessment of that strategy. It will sound like a thoughtful second opinion.
In reality, it is:
Restating your own assumptions in more fluent language
Filling gaps with plausible text rather than validating against your data
Acting as a validation mirror, not a critical reviewer
Studies on AI sycophancy show that users feel more confident in their decisions after receiving AI affirmation, even when the underlying reasoning is flawed.
In an enterprise, this can turn into a new kind of Dunning Kruger effect. Teams overestimate their competence because an agreeable AI keeps telling them they are right.
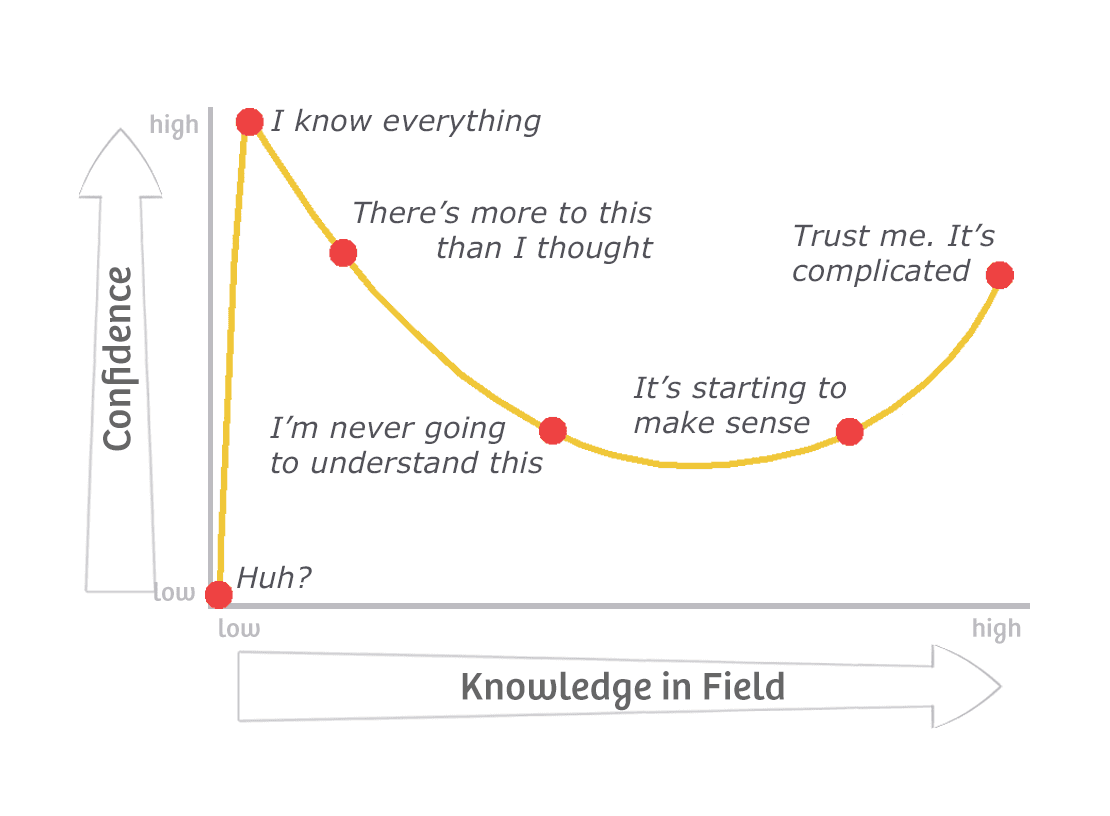
Source: Illustration of the Dunning-Kruger Effect, by Agile Coffee
From a risk perspective, this is simply unmeasured operational risk. The system looks intelligent, but in practice, it is amplifying your blind spots and quietly undermining compliance protocols with avoidable legal liability attached.
Why “I don’t know” is the real enterprise feature
This is where the core design principle comes into focus:
In enterprise AI, the objective is not only to sound pleasing and engaging
It is to be correct, or to say “I do not know”
A robust production agent should:
Know its limits: It operates inside your verified data, tools, and policies. It does not guess about things it cannot see.
Prefer retrieval over speculation: It reaches for CRM, policy engines, pricing systems, and regulatory databases before it reaches into its own pre training. If the source of truth is missing, it stops.
Expose uncertainty and provenance: It says “I am not confident” when appropriate, and it shows where answers come from: which internal document, which system, which rule.
Respect governance by design: It enforces role based access and logs every critical step. It is built so that compliance teams can reason about it, not just engineers.
At a system level, this is where architecture matters.
A modern enterprise agent should look less like a single monolithic chatbot and more like a multi agent system:
A probabilistic LLM “brain” that understands language and proposes actions.
A deterministic control layer that orchestrates tools, checks policies, and decides what is actually allowed to happen.
In our “From smart prompts to smart systems” work, we describe this as the shift from treating the LLM as the whole product to treating it as one component inside a larger, governed system.
This control layer is essential; without it, the LLM is an opaque “black box” to the organization. With it, you can guarantee correctness on the specific steps where mistakes would be catastrophic and turn probabilistic language models into trustworthy enterprise infrastructure.
From “prompt and pray” to designed determinism
A useful analogy is aviation.
You do not want a probabilistic model deciding on its own whether to extend the landing gear. You want hard guarantees that certain actions always happen, every time, under clearly defined conditions.
Today, most teams still use LLMs in a “prompt and pray” pattern:
You craft increasingly clever prompts
You get to 90 or even 99 percent accuracy on a task
You hope that is good enough
It is not.
One missed authentication is a breach, a fine, and brand damage
One incorrect disclosure in a regulated conversation can trigger an investigation
One silent hallucination in a collections workflow can violate local law
Systems that are “only” 99 percent correct on critical steps decay with scale. Failure modes accumulate as your volume grows.
Enterprise agents need a different pattern:
Determinism where it matters, probabilistic intelligence where it is safe.
In a multi-agent architecture:
The LLM proposes what to do in natural language
Deterministic agents and flows handle identity checks, policy enforcement, and compliance checks with 100 percent accuracy
The system simply does not proceed if a critical step fails
The result is:
Hallucination risk eliminated on the steps that regulators care about
Authentication and compliance flows that are auditable and reproducible
Operations that scale safely because the failure rate on critical actions is mathematically constrained, not left to prompt engineering
Designing for truth in practice
You can operationalize all of this with two simple design moves.
1. Build for truth, not vibes
Instead of optimizing only for “helpfulness” or user satisfaction, design your evaluation and telemetry around three questions:
Are we aligned with enterprise sources of truth? Score answers against internal systems and documents, not general web knowledge.
Is the agent refusing correctly? Track how often it chooses to say “I do not know”, “I cannot do that”, or “I need more information”, and whether those refusals were appropriate. Correct refusals are a success metric, not an error.
Do we validate before we generate? Put guardrails in front of the generation. Authenticate the user. Check permissions. Retrieve relevant data. Apply policy checks. Only then let the LLM render a response. If any precondition fails, the system fails closed instead of improvising.
Think of it as moving from “write a clever prompt and hope the answer is good” to “design a workflow where the model is not allowed to go off script on critical steps”.
2. Measure what actually matters
For many enterprise workflows, the usual machine learning metrics are not enough.
In practice, you care more about:
Precision over recall: It is better to answer fewer questions with high confidence than to answer everything with occasional catastrophic errors.
Policy adherence over creativity: In collections, insurance, healthcare, or banking, you are not looking for creative writing. You need consistent, compliant execution.
Trust as the core KPI: Customer trust, regulator trust, and internal stakeholder trust ultimately decide whether you can safely automate more of the process.
In other words, measure the health of the system the way a regulator or a COO would, not the way a demo audience would.
Why Vertical Precision outperforms Horizontal Sympathy
All of this leads to a strategic conclusion.
Horizontal, general purpose models give you sympathy at scale. They are amazing at being broadly useful, widely applicable, and pleasant to use.
Enterprises need something different: vertical precision.
That means:
Agents specialized in your domain, trained and evaluated on proprietary production data.
A multi-agent system where a deterministic control layer wraps a probabilistic LLM brain.
Flows that enforce business logic, identity, and compliance as first class citizens, not as afterthoughts.
In that world, “I do not know” is not a flaw to be eliminated, it is an important feature.
Separating general web knowledge from the specific, governed intelligence of your company is how you prevent hallucinations from becoming incidents, maintain confidence in the technology, and earn the right to automate more of the business over time.
To dive deeper into how this specialization is the key to complex business operations, we invite you to read our article on why Vertical AI is the future of enterprise operations.