Why LLMs Struggle: Math, Structured Data & AI Reasoning Limits

Moveo AI Team
in
✨ AI Deep Dives

Large Language Models are extraordinary at language, but they are not calculators. Their core strength is modeling probability distributions over text, not executing formal logic or arithmetic with guaranteed correctness. For enterprises that require reliability, auditability, and compliance, that difference is decisive.
This article explains why models that feel brilliant with prose often fail with numbers, what is happening under the hood, and how to design systems that produce exact, auditable results in real business workflows.
LLMs are word predictors, not calculators
Transformer-based LLMs optimize for the next token that is most likely to appear, given the context. That objective is perfect for fluent writing, summarization, translation, and code suggestions. It does not ensure that interest, risk, tax, or discount formulas are computed exactly.
Think about it this way. Language is statistical. Arithmetic is rule based. A model can learn that “my name is” often precedes a first name. There is no leeway in “62,62.3 × 73.98” or in “compound 2.75 percent for 13 months using banker’s rounding”. Arithmetic requires deterministic step by step procedures. Close enough is wrong.
Even simple facts like 1 + 1 = 2 are often retrieved as memorized patterns rather than executed as general algorithms. As soon as you move to larger numbers, unfamiliar formats, or intricate rounding policies, the apparent certainty evaporates.
Probability vs. Rule-Based Logic
When an LLM answers with a number, it is producing a sequence of tokens that looks plausible. Mathematics does not reward plausibility. It rewards exactness. The unique, correct digit sequence for a five digit multiplication is a very rare pattern in ordinary text. The model will often choose a more common pattern that seems right to a reader rather than the only correct one required by a ledger.
This is why confident paragraphs from a language model can still hide a single wrong digit that fails reconciliation, triggers a compliance exception, or leads to an unfair customer outcome.
The "Stochastic Parrot" problem applied to numbers
This limitation is rooted in the "Stochastic Parrot Dilemma", a term used to describe LLMs that generate convincing language without a true understanding of the underlying meaning.
LLMs are trained to continue text in a way that matches distributional patterns. They do not possess an internal notion of variables, axioms, or operators with guaranteed semantics. When tasks depend on strict semantics, such as compounding interest on a revolving balance or converting basis points to percentage changes across periods, a generator of plausible text will routinely produce answers that read well and compute poorly.
In regulated settings, this is unacceptable. You need systems that compute exactly and explain how they did it.
→ Learn more: LLM Wrappers vs. Moveo’s Multi-Agent AI: Why Real Outcomes Need Real Architecture
Tokenization is the invisible barrier to numerical reasoning
The most technical root of the LLM math problem lies in how the model tokenizes numbers.
Most LLMs break text into subword tokens optimized for language frequency, not for digit structure. That design choice quietly sabotages arithmetic.
How tokenization undermines numbers
The same quantity can split differently. The number “87439” might become tokens like “874” and “39” in one context, “87” and “439” in another, or a single token elsewhere. The model does not consistently perceive positional value. It sees arbitrary chunks of text.
Formatting changes the statistical pattern. The values 12,345 and 12345 and 12 345 and 12.345 are equal under different locale conventions, but each form produces a different token sequence with different next token priors.
Decimals and scientific notation fracture. The equality among 0.007, 7.0e-3, and 7×10^-3 is not encoded. Each representation tokenizes and behaves differently.
Leading zeros and identifiers distort expectations. A quantity like 000123 can be a code, a SKU, or a padded integer. The tokens around it encourage the model to continue with very different kinds of text.
Longer carry chains are rare in training text. Models may imitate short arithmetic seen frequently, then stumble on seven to ten digit operations where carry propagation must be precise across multiple positions.
This same mechanism explains why models often fail to count characters in a word. For example, “strawberry” may be split into subword pieces rather than individual letters, so the model does not reliably track how many r’s are present.
The result is predictable. Without a number aware representation or an external calculator, the model cannot reliably execute arithmetic across formats, sizes, and policies.
Why context still matters
Context is not a silver bullet for arithmetic, but it is essential for correctness in end to end workflows. The model cannot compute exactly, yet it can select the right data, the right policy, and the right instructions for a deterministic engine if you provide the appropriate context.
Provide authoritative data sources. Identify the source of truth for balances, the correct exchange rate table, and the effective dates that apply.
Define policy and semantics. Specify rounding rules, day count conventions, fee caps, currency handling, and locale formatting as machine checkable constraints.
Describe schemas and fields. Annotate which column represents principal versus interest, which flag denotes hardship programs, and which metric is a regulatory disclosure.
With the right context, the model can orchestrate the correct calculation, even though it should never attempt the arithmetic inside the model layer.
Typical failure modes you will see
Below are concrete failures that appear in real systems.
Long multiplication drift. Ask for 48,793 × 7,604. A plain LLM often produces a result that is off by hundreds or thousands because carry propagation across multiple digits is not consistently learned. The number may even have the right length and look plausible at a glance.
Rounding policy mismatch. A customer refund requires banker’s rounding to two decimals. The model instead applies half up rounding and returns 31.76 where policy requires 31.75. The difference is small in isolation, yet it breaks reconciliation and audit rules at scale.
Locale confusion. The input “12.345” is a decimal in US format and a thousands marker in many EU contexts. An LLM that treats it as 12,345 in one step and 12.345 in another step will silently poison a pipeline.
Unit errors. A pricing task asks for a 25 basis point change, which is 0.25 percent. The model mistakenly applies 25 percent. The narrative looks correct. The number is catastrophic.
Period misinterpretation. An annual rate of 7.5 percent is accidentally treated as a monthly rate in an amortization formula. The payment inflates to an absurd value, yet the explanation sounds convincing.
These are not exotic corner cases. They show up whenever inputs get larger, formats vary, or policy is subtle.
→ Learn more: Fine-Tuning, RAG, or Prompt Engineering? LLM Decision Guide
Hybrid Systems and Programmatic Reasoning
The solution to failures in LLM data processing and numerical reasoning is simple. Do not ask an LLM to be a calculator, ask it to plan, explain, and call one.
A robust hybrid pattern looks like this.
Offload math to tools. Route all arithmetic and policy logic to deterministic calculators and services.
Standardize inputs. Normalize locale, currency, separators, signs, and units before planning.
Fix the rules once. Centralize rounding, interest, and fee policies in a single source of truth.
Verify every result. Add range checks, reconciliation tests, and dual computation on critical amounts.
Use the LLM for orchestration. Let it handle intent, planning, context, and explanations, never final numbers.
This is the architecture that leading teams deploy in production. It keeps language where language shines and moves arithmetic and policy where certainty lives. If you have seen mature AI platforms in the wild, you have probably seen this pattern. It is also the pattern we use when we build enterprise grade agents.
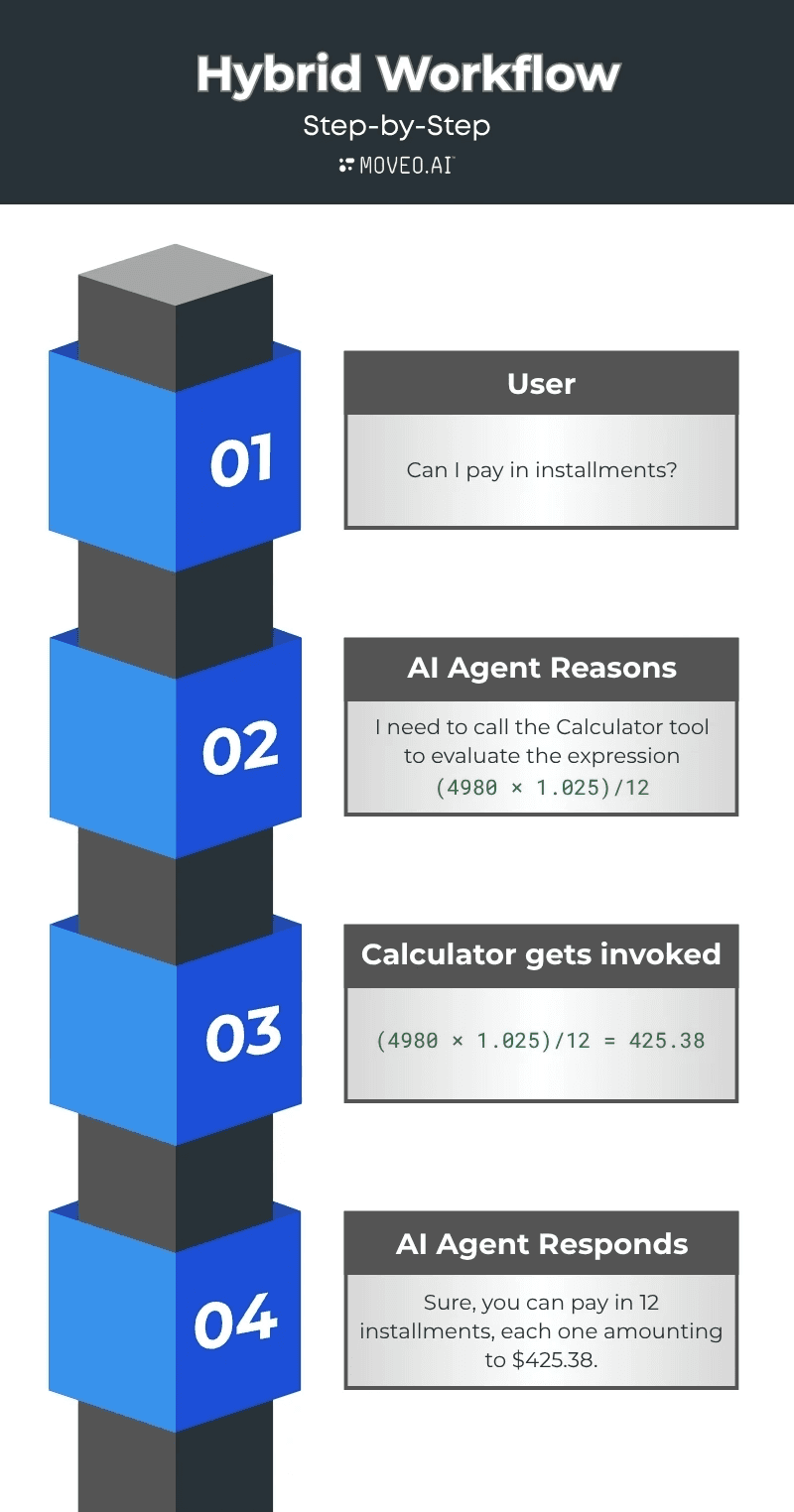
Example: Payment negotiation with compliant installment plans
Scenario
An AI agent negotiates a payment plan for a $4,980 overdue balance. Policy allows a 12 month installment plan with 2.5% interest and standard two decimal rounding.
What a plain LLM tends to do
A plain LLM will often try to “solve” the math inside the model by recalling a familiar looking pattern. It might multiply the balance by a single factor and say the total is 4980 × 1.025, then divide by 12.
This is both oversimplified and very likely to be numerically wrong in practice, since it ignores periodization, fee handling, and rounding policy. The model is predicting tokens that look like a formula rather than executing the correct calculation.
What a hybrid architecture does instead
The model plans the steps and writes the exact formula and policy rules, but it does not compute the numbers. It selects the proper treatment of the 2.5 percent rate, decides whether it is applied as simple annual interest or as a monthly periodic rate for amortization, and specifies the rounding policy.
It then calls a calculator tool to execute the math. The calculator returns the precise monthly payment and the full schedule to the cent. The model explains the result in plain language and logs the inputs, policy version, and outputs for audit. This keeps language and policy interpretation in the model, and it keeps arithmetic in a deterministic component where it is guaranteed to be correct.
What not to overclaim
More calls to the LLM in chain of thought style, a larger model, or even a “smarter” model will not make numbers reliably correct. The limitation is architectural. Transformer based LLMs are probabilistic text generators, not rule exact calculators. Bigger or more elaborate prompting can help the model read and reason about context, but arithmetic belongs in deterministic tools that implement rules, types, and tests.
A practical checklist for leaders
LLMs fail at data analysis and math because of their nature: they are language models probabilistically optimized for fluency, not rule-based precision.
Tokenization strips away the positional structure that arithmetic needs. Training data rarely covers the long tail of real financial and operational calculations.
The solution is a hybrid system in which the model orchestrates and deterministic tools compute. With the right context, policy, and audit trail, you get correctness, explainability, and compliance without sacrificing the conversational intelligence that users value.
This is how modern teams ship AI you can trust.
To successfully deploy LLMs in environments requiring high numerical accuracy and compliance, follow this checklist:
Route all arithmetic and policy bound logic to deterministic tools. Treat this as a hard requirement.
Normalize numeric formats at ingress. Resolve locale, currency, separators, signs, and units before planning.
Codify rounding, interest, and fee policies in a single source of truth. Reuse those rules everywhere.
Add verification layers. Use range checks, reconciliation tests, and dual computation on critical amounts.
Make the model responsible for intent understanding, plan generation, error recovery, context gathering, and clear explanations. Do not let it generate final numbers.
Stay ahead on AI strategy. Follow Moveo.AI on LinkedIn for more expert insights on building production-ready LLM agents and hybrid systems.
Ready to build AI you can trust? Talk to our AI Specialists today to design your robust, compliance-ready LLM solution.