LLM Math e LLM Data: Por que o raciocínio probabilístico falha com a lógica determinística

Moveo AI Team
in
✨ AI Deep Dives

Large Language Models (LLMs) são extraordinários com linguagem, mas não são calculadoras. Sua força central é modelar distribuições de probabilidade sobre texto, não executar lógica formal ou aritmética com correção garantida. Para empresas que exigem confiabilidade, auditabilidade e compliance, essa diferença é decisiva.
Este artigo explica por que modelos que parecem brilhantes com prosa muitas vezes falham com números, o que está acontecendo "sob o capô" e como projetar sistemas que produzam resultados exatos e auditáveis em workflows de negócios reais.
LLMs são preditores de palavras, não calculadoras
LLMs baseados em “transformers” otimizam para o próximo token (unidade de texto) com maior probabilidade de aparecer, dado o contexto. Esse objetivo é perfeito para escrita fluente, sumarização, tradução e sugestões de código. Ele não garante que fórmulas de juros, risco, impostos ou descontos sejam calculadas exatamente.
Pense desta forma: a linguagem é estatística e a aritmética é baseada em regras. Um modelo pode aprender que "meu nome é" frequentemente precede um primeiro nome. Não há margem de manobra em "62,62.3 × 73.98" ou em "compor 2,75 por cento por 13 meses usando arredondamento bancário". A aritmética exige procedimentos determinísticos passo a passo. "Quase certo" está errado.
Mesmo fatos simples como 1 + 1 = 2 são frequentemente recuperados como padrões memorizados, em vez de executados como algoritmos gerais. Assim que você passa para números maiores, formatos desconhecidos ou políticas de arredondamento complexas, a aparente certeza evapora.
Probabilidade vs. Lógica Baseada em Regras
Quando um LLM responde com um número, ele está produzindo uma sequência de tokens que parece plausível. A matemática não recompensa a plausibilidade. Ela recompensa a exatidão. A sequência de dígitos única e correta para uma multiplicação de cinco dígitos é um padrão muito raro em textos comuns. O modelo muitas vezes escolherá um padrão mais comum que parece correto para um leitor, em vez do único correto exigido por um registro contábil.
É por isso que parágrafos confiantes de um modelo de linguagem ainda podem esconder um único dígito errado que falha na reconciliação, aciona uma exceção de compliance ou leva a um resultado injusto para o cliente.
O problema do "Stochastic Parrot" aplicado a números
Essa limitação está enraizada no “Stochastic Parrot Dilemma” (Dilema do Papagaio Estocástico), um termo usado para descrever LLMs que geram linguagem convincente sem um entendimento verdadeiro do significado subjacente.
LLMs são treinados para continuar textos de uma forma que corresponda a padrões distribucionais. Eles não possuem uma noção interna de variáveis, axiomas ou operadores com semântica garantida. Quando as tarefas dependem de semântica estrita, como calcular juros compostos sobre um saldo rotativo ou converter pontos-base (basis points) para variações percentuais entre períodos, um gerador de texto plausível produzirá rotineiramente respostas que são fáceis de ler, mas computacionalmente erradas.
Em ambientes regulados, isso é inaceitável. Você precisa de sistemas que calculem exatamente e expliquem como o fizeram.
→ Saiba mais: LLM Wrappers vs. Moveo Multi-Agent AI: Por que Resultados Reais Exigem Arquitetura Real
A tokenização é a barreira invisível para o raciocínio numérico
A raiz mais técnica do problema de matemática dos LLMs reside em como o modelo tokeniza os números.
A maioria dos LLMs quebra o texto em tokens subpalavras (subword tokens) otimizados para a frequência da linguagem, não para a estrutura dos dígitos. Essa escolha de design silenciosamente sabota a aritmética.
Como a tokenização prejudica os números
A mesma quantidade pode se dividir de forma diferente. O número "87439" pode se tornar tokens como "874" e "39" em um contexto, "87" e "439" em outro, ou um único token em outro lugar. O modelo não percebe consistentemente o valor posicional. Ele vê pedaços arbitrários de texto.
A formatação muda o padrão estatístico. Os valores 12,345 e 12345 e 12 345 e 12.345 são iguais sob diferentes convenções de localidade, mas cada forma produz uma sequência de tokens diferente com diferentes probabilidades de próximo token.
Decimais e notação científica se fragmentam. A igualdade entre 0.007, 7.0e-3 e 7×10^-3 não é codificada. Cada representação é tokenizada e se comporta de maneira diferente.
Zeros à esquerda e identificadores distorcem as expectativas. Uma quantidade como 000123 pode ser um código, um SKU ou um inteiro com preenchimento (padded integer). Os tokens ao redor incentivam o modelo a continuar com tipos de texto muito diferentes.
Cadeias longas de "vai um" (carry chains) são raras no texto de treinamento. Modelos podem imitar operações aritméticas curtas vistas com frequência, mas tropeçam em operações de sete a dez dígitos onde a propagação do "vai um" (carry propagation) deve ser precisa em múltiplas posições.
Esse mesmo mecanismo explica por que os modelos frequentemente falham em contar caracteres em uma palavra. Por exemplo, "strawberry" pode ser dividido em pedaços de subpalavras em vez de letras individuais, então o modelo não rastreia confiavelmente quantos 'r's estão presentes.
O resultado é previsível. Sem uma representação ciente dos números ou uma calculadora externa, o modelo não pode executar aritmética de forma confiável através de formatos, tamanhos e políticas.
Por que o contexto ainda importa
O contexto não é uma bala de prata para a aritmética, mas é essencial para a correção em workflows de ponta a ponta. O modelo não pode calcular exatamente, mas pode selecionar os dados corretos, a política correta e as instruções corretas para um motor determinístico se você fornecer o contexto apropriado.
Forneça fontes de dados autoritativas. Identifique a fonte da verdade para saldos, a tabela de taxas de câmbio correta e as datas de vigência que se aplicam.
Defina políticas e semântica. Especifique regras de arredondamento, convenções de contagem de dias, limites de taxas, tratamento de moeda e formatação de localidade (locale) como restrições verificáveis por máquina.
Descreva schemas e campos. Anote qual coluna representa o principal versus juros, qual flag denota programas de renegociação e qual métrica é uma divulgação regulatória.
Com o contexto certo, o modelo pode orquestrar o cálculo correto, embora nunca deva tentar a aritmética dentro da camada do modelo.
Modos de falha típicos que você verá
Abaixo estão falhas que aparecem em sistemas reais:
Desvio em multiplicações longas. Peça por 48.793 × 7.604. Um LLM puro muitas vezes produz um resultado que erra por centenas ou milhares, porque a propagação do "vai um" (carry propagation) através de múltiplos dígitos não é aprendida consistentemente. O número pode até ter o comprimento certo e parecer plausível à primeira vista.
Incompatibilidade de política de arredondamento. Um reembolso ao cliente requer arredondamento bancário para duas casas decimais. O modelo, em vez disso, aplica o arredondamento para cima e retorna 31,76 onde a política exige 31,75. A diferença é pequena isoladamente, mas quebra regras de reconciliação e auditoria em escala.
Confusão de localidade (locale). A entrada "12.345" é um decimal no formato dos EUA e um marcador de milhares em muitos contextos da UE. Um LLM que trata isso como 12.345 em uma etapa e 12,345 em outra etapa irá silenciosamente corromper um pipeline.
Erros de unidade. Uma tarefa de precificação pede uma mudança de 25 pontos-base, o que é 0,25 por cento. O modelo aplica erroneamente 25 por cento. A narrativa parece correta. O número é catastrófico.
Interpretação errada do período. Uma taxa anual de 7,5 por cento é acidentalmente tratada como uma taxa mensal em uma fórmula de amortização. O pagamento infla para um valor absurdo, mas a explicação soa convincente.
Estes não são casos extremos exóticos. Eles aparecem sempre que as entradas ficam maiores, os formatos variam ou a política é sutil.
→ Saiba mais: Fine-Tuning, RAG ou Prompt Engineering? O guia para customização de LLMs
Sistemas Híbridos e Raciocínio Programático
A solução para falhas no processamento de dados e raciocínio numérico de LLMs é simples. Não peça a um LLM para ser uma calculadora, peça a ele para planejar, explicar e chamar uma.
Um padrão híbrido robusto se parece com isto:
Delegue matemática para ferramentas. Encaminhe toda a lógica aritmética e de políticas para calculadoras e serviços determinísticos.
Padronize as entradas. Normalize localidade, moeda, separadores, sinais e unidades antes do planejamento.
Fixe as regras uma vez. Centralize as políticas de arredondamento, juros e taxas em uma única fonte da verdade.
Verifique cada resultado. Adicione verificações de intervalo, testes de reconciliação e computação dupla em valores críticos.
Use o LLM para orquestração. Deixe-o lidar com a intenção, planejamento, contexto e explicações, nunca com os números finais.
Esta é a arquitetura que equipes líderes implantam em produção. Ela mantém a linguagem onde a linguagem brilha e move a aritmética e a política para onde a certeza reside. Se você viu plataformas de IA maduras em operação, provavelmente viu esse padrão. É também o padrão que usamos quando construímos agentes de nível empresarial.
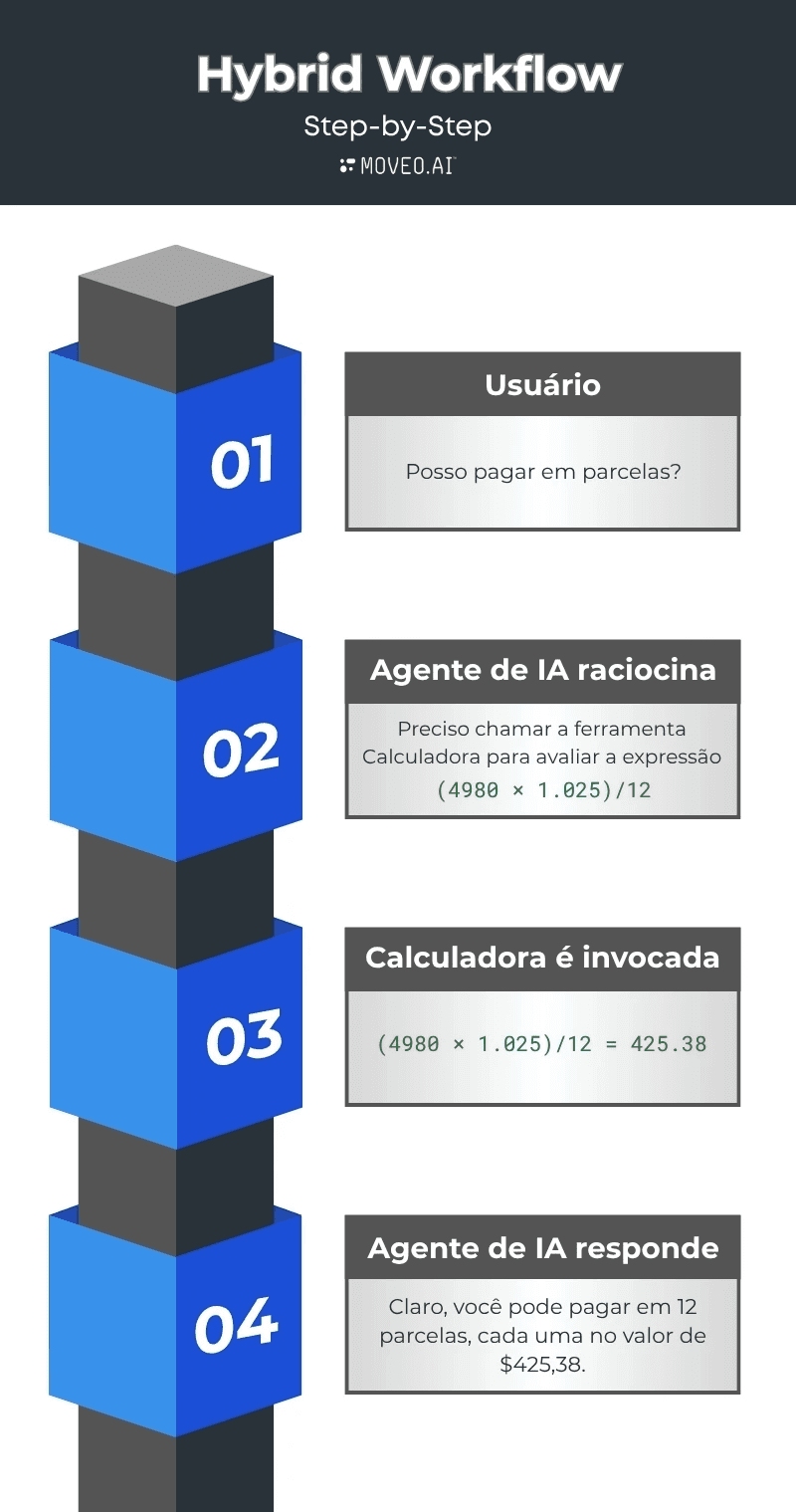
Exemplo: Negociação de pagamento com planos de parcelamento
Cenário
Um agente de IA negocia um plano de pagamento para um saldo devedor de $4.980. A política permite um plano de 12 parcelas com 2,5% de juros e arredondamento padrão de duas casas decimais.
O que um LLM puro tende a fazer
Um LLM puro muitas vezes tentará "resolver" a matemática dentro do modelo, lembrando um padrão familiar. Ele pode multiplicar o saldo por um único fator e dizer que o total é 4980 × 1.025, e então dividir por 12.
Isso é simplificado demais e é muito provável que esteja numericamente errado na prática, pois ignora a periodização, o manuseio de taxas e a política de arredondamento. O modelo está prevendo tokens que parecem uma fórmula, em vez de executar o cálculo correto.
O que uma arquitetura híbrida faz
O modelo planeja os passos e escreve a fórmula exata e as regras da política, mas não computa os números. Ele seleciona o tratamento adequado da taxa de 2,5%, decide se ela é aplicada como juros anuais simples ou como uma taxa periódica mensal para amortização, e especifica a política de arredondamento. Em seguida, ele chama uma ferramenta de calculadora para executar a matemática.
A calculadora retorna o pagamento mensal preciso e o cronograma completo, centavo por centavo. O modelo explica o resultado em linguagem simples e registra as entradas, a versão da política e as saídas para auditoria. Isso mantém a interpretação da linguagem e da política no modelo, e mantém a aritmética em um componente determinístico onde é garantido que esteja correta.
O que não superestimar
Mais chamadas ao LLM no estilo chain of thought (cadeia de pensamento), um modelo maior, ou mesmo um modelo "mais inteligente" não tornarão os números confiavelmente corretos. A limitação é arquitetônica.
LLMs baseados em transformer são geradores de texto probabilísticos, não calculadoras de regras exatas. Prompts maiores ou mais elaborados podem ajudar o modelo a ler e raciocinar sobre o contexto, mas a aritmética pertence a ferramentas determinísticas que implementam regras, tipos e testes.
Um checklist prático para líderes
LLMs falham em análise de dados e matemática devido à sua natureza: são modelos de linguagem otimizados probabilisticamente para fluência, não para precisão baseada em regras.
A tokenização remove a estrutura posicional que a aritmética necessita. Os dados de treinamento raramente cobrem a long tail dos cálculos financeiros e operacionais reais.
A solução é um sistema híbrido em que o modelo orquestra e as ferramentas determinísticas computam. Com o contexto, a política e a trilha de auditoria corretos, você obtém exatidão, explicabilidade e compliance sem sacrificar a inteligência conversacional que os usuários valorizam.
É assim que equipes modernas entregam IA em que você pode confiar.
Para implantar LLMs com sucesso em ambientes que exigem alta precisão numérica e compliance, siga esta lista de verificação:
Encaminhe toda a lógica aritmética e vinculada a políticas para ferramentas determinísticas. Trate isso como um requisito indispensável.
Normalize os formatos numéricos na ingestão. Resolva localidade, moeda, separadores, sinais e unidades antes do planejamento.
Codifique as políticas de arredondamento, juros e taxas em uma única fonte da verdade. Reutilize essas regras em todos os lugares.
Adicione camadas de verificação. Use verificações de intervalo, testes de reconciliação e computação dupla em valores críticos.
Torne o modelo responsável pelo entendimento da intenção, geração de plano, recuperação de erros, coleta de contexto e explicações claras. Não o deixe gerar os números finais.
Mantenha-se à frente na estratégia de IA. Siga a Moveo.AI no LinkedIn para mais insights de especialistas sobre a construção de agentes LLM e sistemas híbridos prontos para produção.
Pronto para construir IA em que você pode confiar? Fale com nossos especialistas em IA hoje mesmo para projetar sua solução de LLM robusta e pronta para compliance.